Breaking News: Meta's KernelEvolve Delivers 60% Inference Boost on NVIDIA GPUs
Meta has released details of a new autonomous AI system, KernelEvolve, that dramatically accelerates the optimization of low-level chip instructions—known as kernels—across its vast fleet of heterogeneous hardware.
The system, built by Meta's Ranking Engineer Agent team, achieved a 60% improvement in inference throughput for the Andromeda Ads model on NVIDIA GPUs and a 25% training throughput gain on Meta's custom MTIA chips, according to a paper to be presented at ISCA 2026.
“KernelEvolve compresses weeks of expert engineering time into hours of automated search and evaluation,” said a Meta AI researcher. “It treats kernel optimization as a search problem, using an LLM to iteratively generate and test hundreds of candidates.”
Background: The Kernel Bottleneck
Meta operates a large, heterogeneous infrastructure including NVIDIA GPUs, AMD GPUs, its own MTIA silicon, and CPUs. To run AI models efficiently, high-level operations must be translated into chip-specific optimized kernels.
Standard operators like matrix multiplications are covered by vendor libraries, but production workloads require many custom operators across ranking models. Hand-tuning kernels for every new chip generation and ML model architecture simply does not scale.
How KernelEvolve Works
KernelEvolve automates this process by treating kernel optimization as a search problem. A purpose-built job harness evaluates each candidate kernel, feeds diagnostics back to a large language model, and drives a continuous search over hundreds of alternatives.
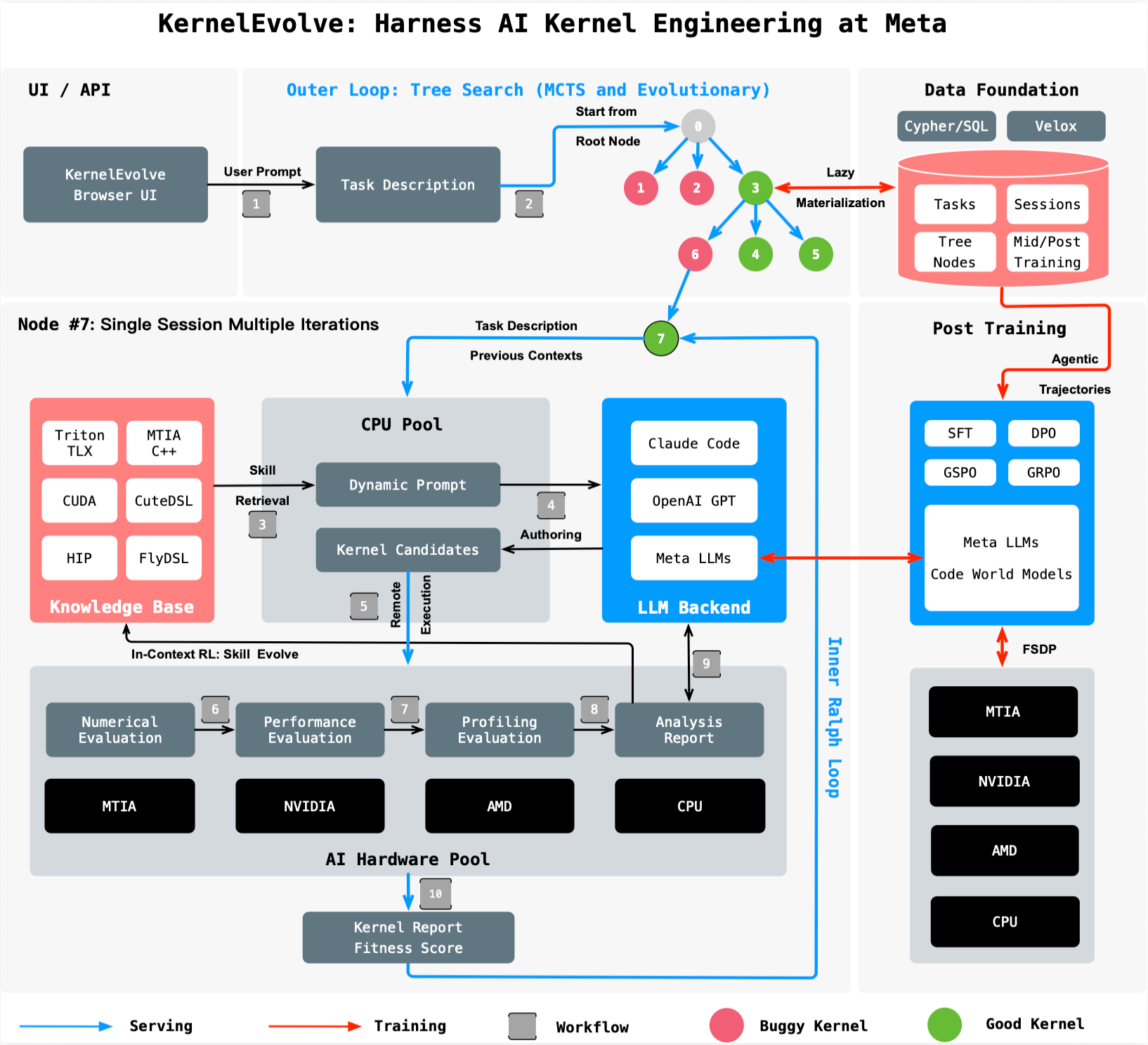
It generates kernels in high-level domain-specific languages such as Triton, Cute DSL, and FlyDSL, as well as low-level languages including CUDA, HIP, and MTIA C++. This enables broad applicability across public and proprietary hardware.
What This Means
KernelEvolve represents a fundamental shift in how AI infrastructure is optimized. By automating the tedious work of kernel authoring and cross-hardware debugging, Meta frees its engineers to focus on higher-level innovation.
The system is not limited to ads ranking—it is generally applicable to any AI model running on Meta's diverse hardware. With the number of models and hardware types growing rapidly, agentic systems like KernelEvolve are becoming essential to maintain performance at scale.
“This technology is a key enabler for Meta's AI ambitions,” the researcher added. “It allows us to keep pushing the boundaries of model complexity without being bottlenecked by manual kernel engineering.”